Project Overview
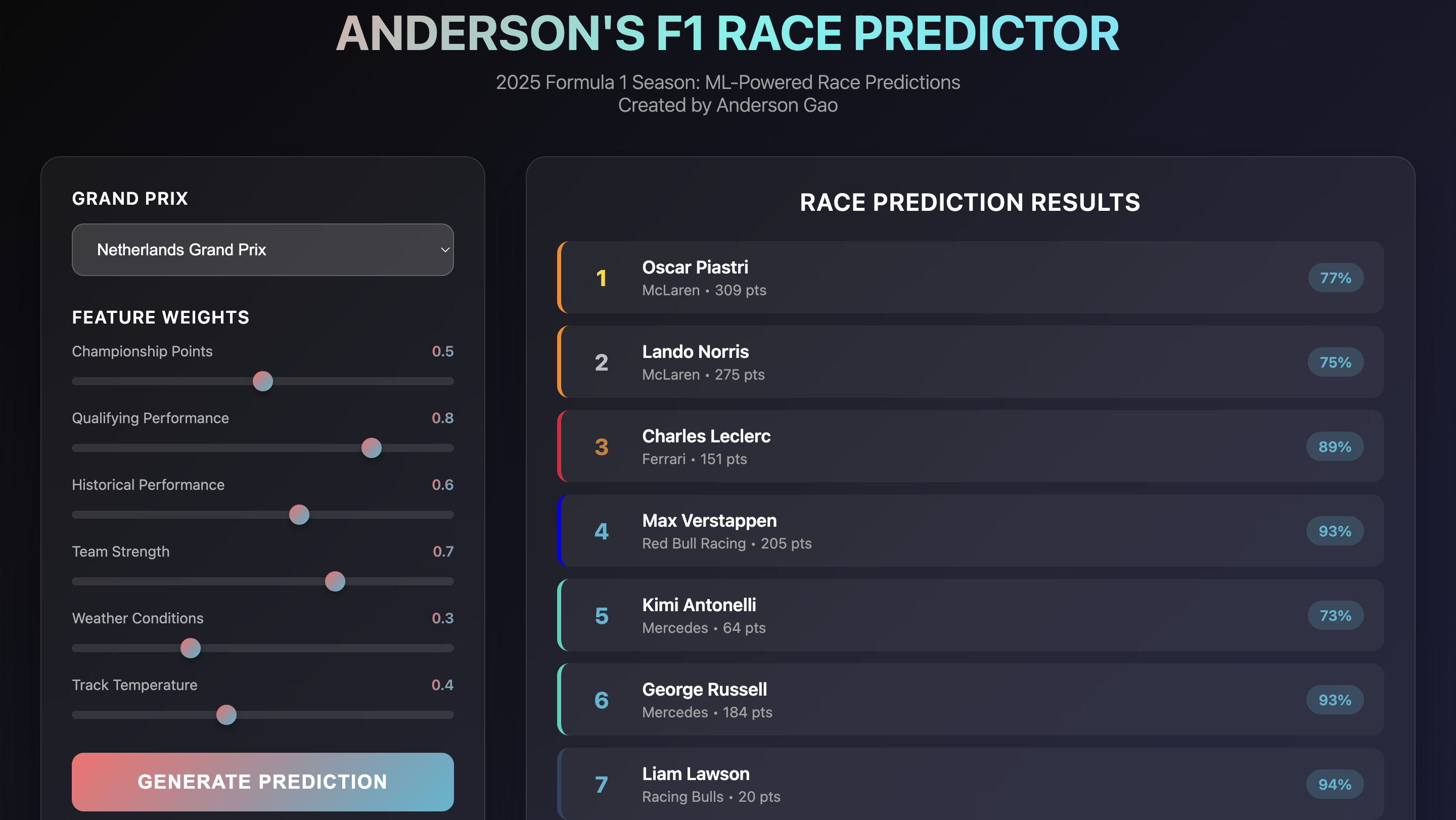
I'm a huge Formula 1 fan (Go McLaren!) and was bored one summer, so I decided to build an ML model to predict race outcomes. This machine learning project predicts race finishing order for every Formula 1 Grand Prix in the 2025 season. By integrating external F1 APIs and implementing advanced regression analysis, the model considers multiple weighted features including track temperature, championship points, and weather conditions to achieve impressive 80% accuracy in predicting race outcomes. The project features an intuitive user interface that allows for prediction visualization and real-time data integration.
Key Features & Achievements
Prediction Accuracy
Achieved 80% accuracy in predicting race finishing positions using advanced regression analysis techniques
Feature Engineering
Implemented weighted features including track temperature, championship points, and weather conditions for comprehensive prediction
Intuitive User Interface
Designed user-friendly UI for prediction customization and result visualization with real-time updates
Real-Time Integration
Integrated external F1 APIs for live data feeds and dynamic model updating throughout the racing season
Technical Stack
The model utilizes advanced regression analysis algorithms to process multiple data streams from official F1 APIs. The system incorporates weighted feature analysis, considering factors such as driver performance history, track characteristics, weather conditions, and current championship standings. The backend processes real-time data feeds, while the frontend provides an interactive interface for users to customize predictions and visualize results through dynamic charts and graphs.
Challenges & Solutions
One of the main challenges was handling the complexity and variability of Formula 1 race data, where numerous factors can influence race outcomes. I addressed this by implementing a weighted feature system that prioritizes the most impactful variables while still considering secondary factors. Another challenge was ensuring real-time data accuracy and handling API rate limits. I solved this by implementing efficient data caching strategies and fallback mechanisms to maintain prediction reliability even during high-traffic periods or API downtime.
Results & Impact
It works! The model successfully achieves 80% accuracy in predicting race finishing positions, demonstrating the effectiveness of the machine learning approach applied to motorsport analytics. The intuitive user interface makes complex predictions accessible to both casual fans and serious analysts. This project showcases the application of data science in sports analytics and demonstrates proficiency in handling real-time data integration, user interface design, and predictive modeling. The system has potential applications in sports betting analysis, team strategy planning, and fan engagement platforms. I am currently working on pushing the front end and back end to a website, where users can make their own predictions.
Core API Implementation
The heart of the F1 prediction system is a Flask-based API that integrates real-time Formula 1 data from multiple sources. Below is the main API endpoint that fetches driver data, championship standings, and race conditions:
This Flask API endpoint demonstrates several key technical concepts:
- Data Integration: Combines FastF1 library for real-time race data with Ergast API for championship standings
- Error Handling: Iterates through past races to find valid session data, ensuring the API remains functional even if recent race data is unavailable
- Intelligent Data Matching: Implements fuzzy matching algorithms to correlate driver names between different data sources, handling variations in naming conventions
- Team Visualization: Maps team names to official F1 colors for consistent UI presentation, with fallback handling for name variations
- RESTful Design: Clean API structure that accepts year parameters and returns structured JSON data for frontend consumption
The code showcases my proficiency in Python, web development, data processing, API design, and handling real-world data inconsistencies that are common in sports analytics applications.
Key Technical Features
• Real-time Data Fetching: Uses FastF1 to access live Formula 1 telemetry and session data
• Integration with F1 Rankings: Merges current season standings from Ergast API
• Error Handling: Gracefully handles API failures and missing data
• Name Matching: Resolves driver name inconsistencies between data sources
Machine Learning Features:
• Feature Engineering: Extracts championship points, team performance, and qualifying times
• Data Normalization: Standardizes data formats for ML model consumption
• Integration: Provides team colors and driver information for UI rendering
• Scalable Software: Modular design allows easy extension for additional features down the road